

Ce matin, il m’était impossible de faire quoi que ce soit sur mon serveur Linux de supervision. Comme si le disque était en lecture seule. Voilà comment j’ai découvert la notion d’inodes sous Linux.
Présentation.
Avant d’aller plus loin, je pense qu’il faut expliquer ce qu’est un inode.
Voici une définition du site Wikipédia
À chaque fichier correspond un numéro d’inode (i-number) dans le système de fichiers dans lequel il réside, unique au périphérique sur lequel il est situé.
Chaque fichier a un seul inode, même s’il peut avoir plusieurs noms (chacun de ceux-ci fait référence au même inode).
Chaque nom est appelé link. Les inodes peuvent, selon le système de fichiers, contenir aussi des informations concernant le fichier, tel que son créateur (ou propriétaire), son type d’accès (par exemple sous Unix : lecture, écriture et exécution), etc. Tous les inodes sont contenus dans la table des inodes
Message d’erreur.
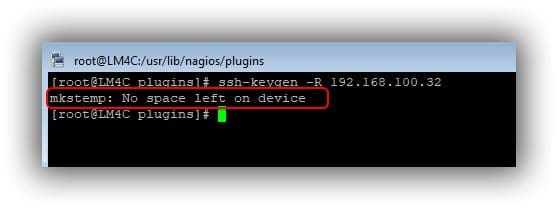
Généralement l’erreur intervient lorsque vous voulez créer ou modifier un fichier sur votre disque, l’erreur disque plein. Voici un exemple
# ssh-keygen -R 192.168.100.32
Comment savoir si nous n’avons plus d’inodes de disponible sur notre serveur ? grâce à la commande suivante vous allez être fixé très rapidement.
#df –i
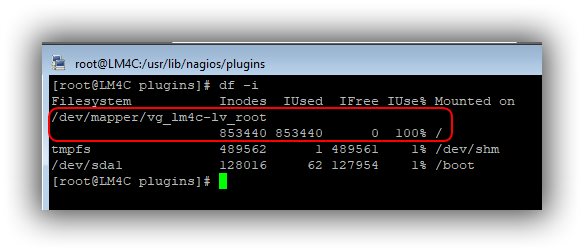
Comme vous pouvez le constater, je n’ai plus d’inodes de disponible sur la partition /dev/mapper/vg_lm4c-lv_root.
Pour savoir où sont ces fichiers, on peut utiliser la commande suivante : elle va chercher le nombre de fichiers dans chaque répertoire. On commence par la racine /.
# for i in /*; do echo -n $i " " ; find $i |wc -l; done | sort -n -k2
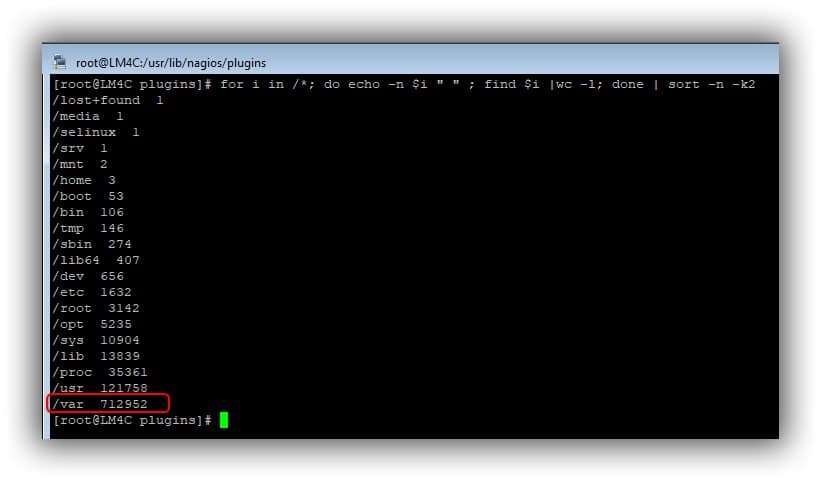
Pour savoir d’où vient le problème, il faudra peut-être adapter la commande. Par exemple ici je vais analyser le répertoire /var, car je vois que c’est lui qui consomme le plus d’inode.
# for i in /var/*; do echo -n $i " " ; find $i |wc -l; done | sort -n -k2
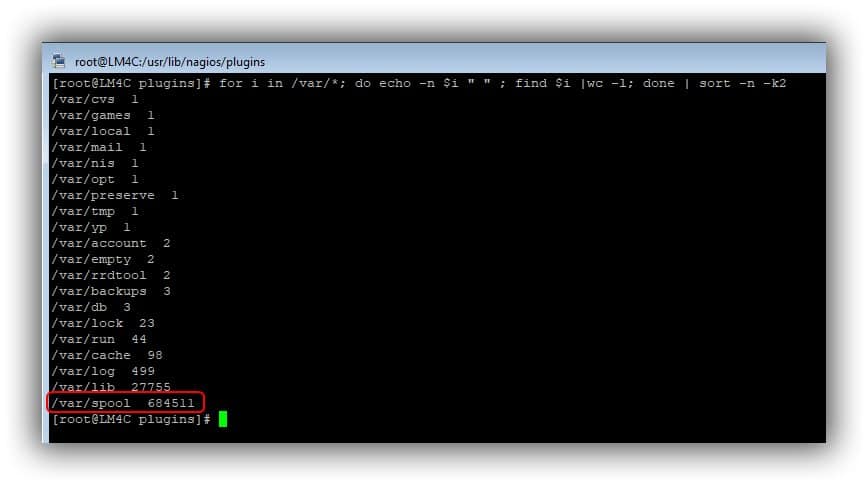
Ici le répertoire qui consomme des inodes est le répertoire spool.
Le résultat est présenté très simplement : le nom du répertoire et le nombre de fichiers associés. En utilisant ce résultat, on peut continuer avec une commande similaire mais en remplaçant /* par /le-repertoire/* …et ainsi de suite jusqu’à trouver le répertoire coupable !
Une fois trouvé le bon répertoire (/var/spool/centreontrapd dans mon cas), il faut encore faire le ménage avec la commande rm -f *centreon*.
Malheureusement vu la quantité de données à supprimer j’ai ce message d’erreur :
Ceci est dû à une limitation de la commande rm, qui ne permet pas de gérer un grand nombre d’arguments (le joker ‘*’ est développé par le shell en une série d’arguments).
Pour ne pas s’embêter à supprimer par lot les fichiers (surtout si vous en avez des milliers), vous pouvez utiliser cette commande à l’intérieur du répertoire où ils se trouvent :
#find . -name "*fichier_à_supprimer*" -exec rm {} \;
Une fois que notre commande s’est terminée, refaite un df –i et vous verrez que vous avez de nouveau des inodes de disponible.

That’s All.



Très bien. Peux être serait-il intéressant de dire que cela peut être supervisé?
Bonne continuation.
Bonjour,
merci pour ces encouragements. J’espère que les tutoriels vous plaisent et vous sont surtout utiles.
A bientôt
Merci pour cette découverte et mise en garde. Je vais mettre cet article dans mes bookmarks. ça peut toujours servir.
Merci encore ! ;-)
Jo
Un fidèle lecteur